
The landscape of software testing is changing. In the hyper-competitive world of technology, speed and quality are often seen as opposing forces. We are told to “move fast and break things” if we are to succeed in getting our products into the hands of users before our competition beats us to the punch. This often times means sacrificing quality and confidence in the name of getting new features out the door.
While this trade-off sometimes makes sense, it inevitably comes back to haunt you in the form of technical debt, bugs, decreased user confidence, and blockers for your product and engineering teams. As those teams scale, we aim to ship faster and faster. Meanwhile, the frameworks and technologies we build on top of become more dynamic. Traditional approaches to test automation are not only falling short, but they are becoming a burden rather than an asset.
Testing architecture
In order to understand where Rainforest automation fits into a companies testing strategy and the enormous benefits it brings, we first need to understand the basics of testing architecture.
There are many layers to properly testing an application and the many services it interacts with. For simplicity, we will represent general testing architecture with an oversimplified model: The Test Pyramid.

This model originally comes from Mike Cohn’s book “Succeeding with Agile” and consists of three layers:
- Unit tests
- Service tests (a.k.a. integration tests)
- UI tests
This model does not adequately capture the many layers of testing modern applications, but the mental model is ideal for generalizing and understanding the concepts of testing.
At the bottom of the pyramid, tests are very granular and are executed quickly and at a very low cost (essentially free). As we move up the pyramid, tests become more generalized, slower, and more expensive (both in terms of execution and creation/maintenance).
Consider the following tech stack for our theoretical application:

In our example, the frontend (User Interface) is a React app which talks to our Backend API. That API is responsible for reading/writing to the database, talking to our other microservices, and interacting with external third-party APIs.
Layer 1: unit tests
The bottom layer of the pyramid is the first line of defense against bugs. It’s used to test specific pieces of our tech stack. In particular, it tests “units” of each application/service, which is a somewhat arbitrarily defined “chunk” of code. There are a lot of nuanced decisions to be made by your engineering team around what defines a “unit” and how they should be tested, but that’s outside the scope of this article.
Each red box in our tech stack is tested with its own set of unit tests.
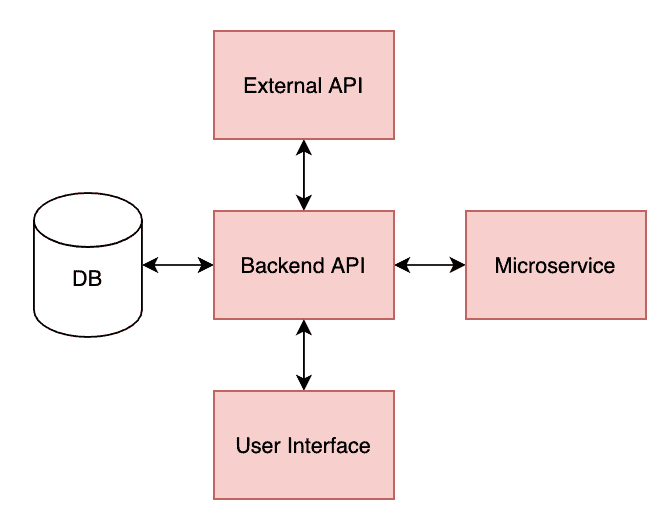
Unit tests are performed in complete isolation and in artificial or simulated environments. This means the React unit tests know nothing about our Backend API, and vice versa. We are testing the internal pieces of each application and making sure the individual parts work as intended. An example of this is testing a single React component – for our example, we’ll use a simple button.
const MyButton = ({ onClick, text }) => (
{text}
);Our unit tests will test two things:
- the button renders with the text that is provided to it
- when the button is clicked, it invokes the onClick provided function
Using Jest + Enzyme (which are standard libraries for testing React applications), our unit test looks something like:
describe('Button', () => {
beforeEach(() => {
props = {
text: 'hello world',
onClick: jest.fn()
};
component = mount();
});
it('renders the text', () => {
expect(component.text()).toEqual('hello world');
});
it('invokes onClick prop when clicked', () => {
component.simulate('click');
expect(props.onClick).toHaveBeenCalled();
});
});Fantastic, the tests passed and we are now confident that our React code works. This is the standard way of testing a simple component and there is nothing wrong with this, but there are important things to note:
- This test runs in complete isolation – it has zero context about where it will be used in the application.
- It makes a naive assumption that the onClick function being provided to it is valid. By “valid” I mean that the onClick value is actually a function (I could easily provide a number by accident), and the function isn’t riddled with bugs. In short, it assumes that the engineer will use MyButton correctly.
- We are writing code to test code.
We can mitigate the risk of #1 with solutions like static type checking, but concern #2 is inherently vulnerable to bugs and false positives. Should you write code to test the code that tests your code? Every time we writing unit tests, we make the assumption that our test code is valid – which is not always true.
This is not a huge problem though – remember that this is only layer 1. We cannot expect layer 1 to catch all the bugs. If we flip our pyramid upside and visualize it as a funnel, we can see how the possible number of bugs are reduced as we push the code through the layers
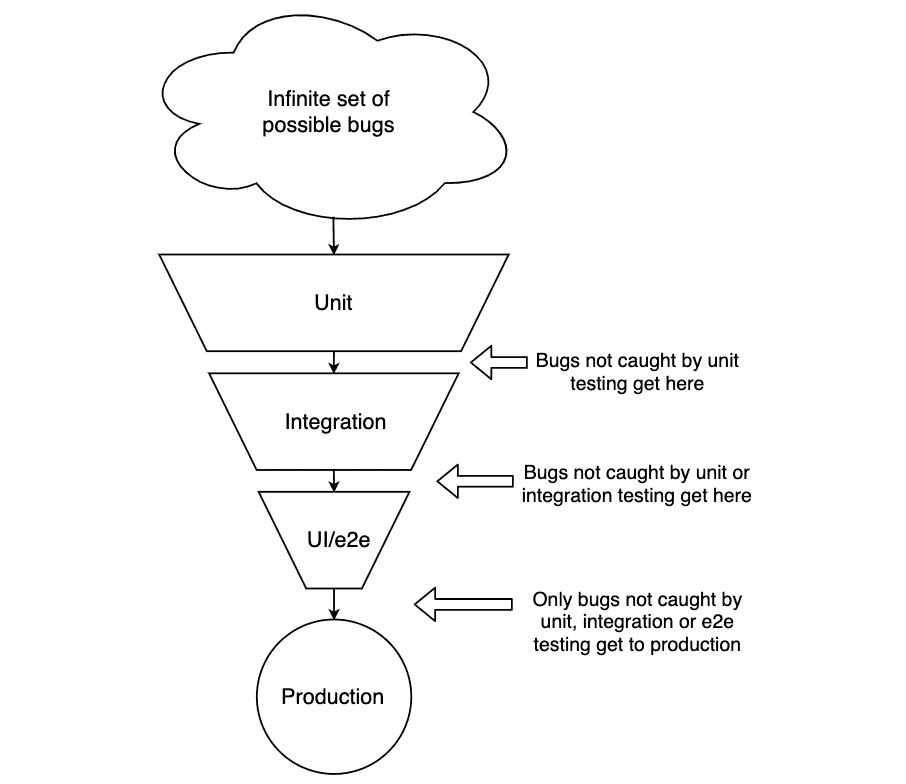
Now that we are relatively confident that our code works on a granular level, we can move to the next layer of our test pyramid.
Layer 2: service (integration) tests
The terms “service” and “integration” are interchangeable, and they are both quite vague. Similar to our vague definition of “units” in our unit tests, our “integration tests” live at the boundaries of our applications and test its interactions with external services, such as databases and third-party APIs.
In our visualization, we are testing the red connections between applications/services.
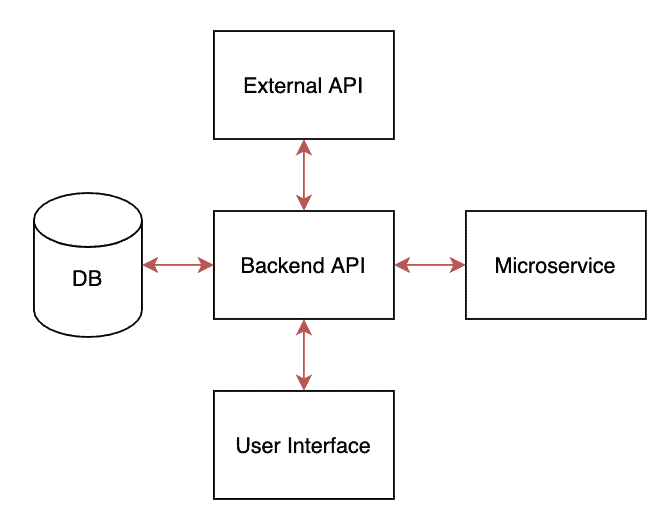
Integration tests can not be run in an entirely isolated, simulated environment like our unit tests. They require some testing infrastructure to be set up so we can test the interactions between services.
For example, we want to test that our Backend API properly interacts with our database. The execution of one of the tests might look something like:
- Start the database and API
- Connect the API to the database
- Make an HTTP to the API that requires it to write to the database
- Read from the database to ensure the expected data has been written
Not only do we test the interaction between API <=> DB, but this can also be seen as a superset of our unit tests. If our integration tests pass, it’s reasonable to assume the API’s code is working as expected (which is what our unit tests are for). We get redundancy for free!</=>
We can test our integration with third-party services in a similar way:
- Start the API
- Connect the API to the third-party service
- Trigger a function in our API that requires it to read from the third-party service
- Check that our API handles the response correctly
The important things to note for our integration tests:
- We are no longer running tests in complete isolation. We need to setup a testing environment (a functional clone of our production application, minus some data and scaling capabilities) which has the added benefit of testing the infrastructure that runs our application. It’s ideal for this environment to mirror our production environment as closely as possible.
- Although we are not in complete isolation anymore, we have still isolated specific pieces of our tech stack. It’s possible that bugs could occur when multiple services interact with each other. In essence, we are just testing larger “units” of our tech stack. We must control the state of the system, which is obviously necessary to execute the tests, but does not necessary emulate “real world” input that comes from users.
- We are still writing code to test our code. It’s possible that our testing code could have bugs.
There are many different sub-layers to our integration layer, and these become more complex as your tech stack grows. A complex microservice architecture can be great when you have many teams working in parallel, but you need to ensure that the integrations don’t break. These risks are mitigated with approaches like contract testing.
Layer 3: UI tests
Our final layer allows us to test our application in a “real world” scenario. We are no longer testing individual pieces – instead, we are testing our entire tech stack from the perspective of our end-user.
An industry standard approach to UI testing is by writing automation scripts with Selenium. There are other technologies and solutions, but they ultimately take the same approach – DOM based testing. An exception to this would be using humans to manually do your QA, but for obvious reasons this it not as scalable as an automated approach.
Our different applications/services interact with each other, but our users ultimately interact with our services through a single entry point: the user interface. This interaction is shown as the red arrows below.
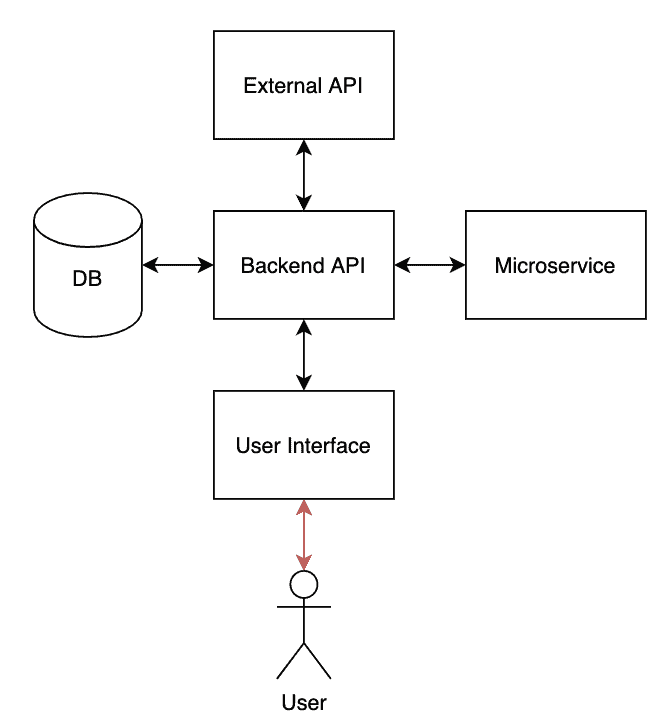
Due to the requirements of properly testing the interaction, we are forced to implicitly test our entire tech stack:
- An entire testing environment is required, which means running each of our applications/services.
- Tests must be run in an actual web browser (or equivalent environment for things like desktop apps, mobile apps, etc).
- Tests must be executed only by interacting with the UI – just like a real user would – and checking that the UI is updated properly.
It may not be immediately clear why this is implicitly testing our entire tech stack. Consider what happens when you click a button in the UI:
In layers 1 & 2, we tested each of these “units” individually. Even though this is a simple button click, we’ve tested that many pieces of our tech stack work in concert with each other.
The industry standard approach to layer 3 is DOM-based testing with tools like Selenium and Cypress. However, Rainforest Automation is the future of UI testing.