
Flaky tests are automated software tests that sometimes pass and sometimes fail without an obvious reason. Often these tests will work well for a while, then occasionally start to fail. If the test passes on a second or third try without any obvious reason for the failures, the tester typically chalks it up to a glitch in the system and ignores the failed test result.
If the test continues to perform inconsistently, the tester may stop running that test altogether, losing potentially critical test coverage.
Either way, if failed test results are being ignored or tests aren’t being run, real bugs can get missed.
While it may seem like nothing has changed between passing and failing test runs, in reality, there’s always something that changed to cause the failed test result.
This article will help you:
- Identify common causes of flaky tests.
- Find the best way to handle flaky tests that do arise.
- Learn the easiest way to uncover the root cause of a flaky test.
- Develop good practices to prevent flaky tests.
Note: If you’re a current Rainforest user and you’re looking for troubleshooting tips, see this article.
It’s easier to find the root cause of automated test failures with Rainforest QA than any code-based testing framework. Talk to us to see the difference.
Common Causes of Flaky Tests
In an ideal world, you’d be able to test your application in the exact same test environment and return the exact same results every time. While some testing software can get close to this ideal (by using virtual machines with standard configurations instead of real devices, for example), the reality is that it can be very difficult to control every aspect of your test run.
This is especially true for end-to-end (E2E) tests because there are so many moving parts and dependencies. Some teams believe it’s nearly impossible to mitigate flaky tests with automated E2E testing and therefore skip automating UI tests altogether. But E2E testing plays an essential role in ensuring a high quality user experience. Even if automating your E2E tests means you encounter a few flaky tests, automation can still significantly improve the speed and repeatability of your testing.
Plus, there are ways to mitigate flaky tests.
The first step is to understand what can cause flaky tests. Even though the term ‘flaky test’ may suggest it’s always an issue with the test that causes inconsistent results, there are many other factors that could cause inconsistent results.
Three of the most common causes of test flakiness, other than issues with the test itself, are:
- Test environment issues. This includes issues such as the application loading too slowly (e.g., the test tries to execute an action before the page finished loading), the application crashing or going offline intermittently, network latency, or interactions with third-party APIs failing or running slower than usual.
- Non-determinism in app behaviors. Non-determinism is when a feature is designed to display different results or behaviors between runs even when given the same input. For example, you may be trying to test search functionality where the last step of the test is to verify that results appear. To verify this, the test looks for a particular title to appear somewhere on the first page. Perhaps that specific title appears on the first page nine times out of 10, but on the tenth run, it shows up on the second page, causing the test to fail.
- Issues with data management. If multiple tests use the same test user account, then running tests at the same time could create collisions. For example, one test might fail to log in because the account is already in use by another test.
When a flaky test fails, it may be because of an issue in the test environment that won’t carry over into the production environment. However, some issues such as network errors, slow load times, or problems with third-party APIs could carry over and ultimately end up affecting the end user. If you ignore flaky test results, there’s a good chance you’ll be ignoring real problems.
What to Do with Flaky Tests
While ignoring failed flaky test results isn’t a good idea, it’s not always practical to spend a lot of time troubleshooting inconsistent tests. There are several options when it comes to handling flaky tests and it may be helpful to use all of them in different situations. However, it’s important to make sure you’re deliberately choosing the best response to maintain your team’s standards of quality assurance (QA).
Your options for what to do with flaky tests include:
- Immediately search for the cause of the failure and fix it. While this is the ideal solution, it simply isn’t practical on a large scale. But it’s always the first option, and may be the only safe option if the test is covering a critical user path.
- Re-run all failed tests, and if they pass, move on. This option saves time in the moment, but can cause your test suite to become less reliable over time if you never address the underlying issue. It’s often a good idea to determine specific criteria for when this option can be used. Some examples of situations that might always call for a re-run include timing issues or temporary issues with the test environment that won’t carry over into production. You may also want to specify how many times in a row this option can be used for one test, and quarantine tests that are particularly flaky.
- Temporarily disable the test or remove it from the test run group. This may be a good option if release speed is more important than dealing with inconsistencies the test might uncover. It’s important that you make a plan to fix the test in the future and hold your team accountable to that plan.
- Move tests that produce inconsistent results into a separate test run group. This creates a clear expectation that only the tests in this group are flaky, restoring confidence in the rest of your test suite. It’s still good to run the tests in the flaky group, because you can discover other bugs if the test fails on a step other than the one known to be flaky. The results of this separate group would be reviewed with each test run, but a failure in this group would not serve as a gating criteria to hold a release.
- Delete the test. If the test has never found critical bugs and isn’t covering an important user path, you may want to reconsider whether you actually need the test.
Regardless of how you handle flaky tests, it’s important to keep track of which tests produce inconsistent results, how you handled each failed test result, and the reason for the test failure whenever possible. Documenting each flaky test and what you did about it helps you and your team maintain faith in the test suite and develop your own best practices to prevent flakiness. It also helps you notice recurring patterns that could potentially be resolved.
For instance, if your app is loading slowly in the test environment, consider upgrading your test machines and the associated components.
The Easiest Way to Find the Root Cause of Flaky Tests
To find the root cause of flakiness, you have to determine what’s changing between test runs. But this can be a tedious task without the right tools.
With most open-source and code-based testing tools, you’ll end up sorting through lines of code in order to understand why some tests pass and others fail, which can be very time-consuming. If testing is normally handled by non-technical QA team members, the task of discovering why each test failed will have to be handled by someone outside the QA team — in most cases, a developer. This means finding the root cause of flaky tests could create a bottleneck in the software development lifecycle.
Rainforest QA solves this problem by making it much easier and faster for anyone to understand why a test failed, providing video replays and detailed test reports for every test.
Instead of using code to test code, Rainforest QA uses an intuitive visual editor to create test cases. To write or edit any test step, you choose an action (such as “click” or “fill”), then click-and-drag the mouse to take a screenshot of the element you want to apply the action to.
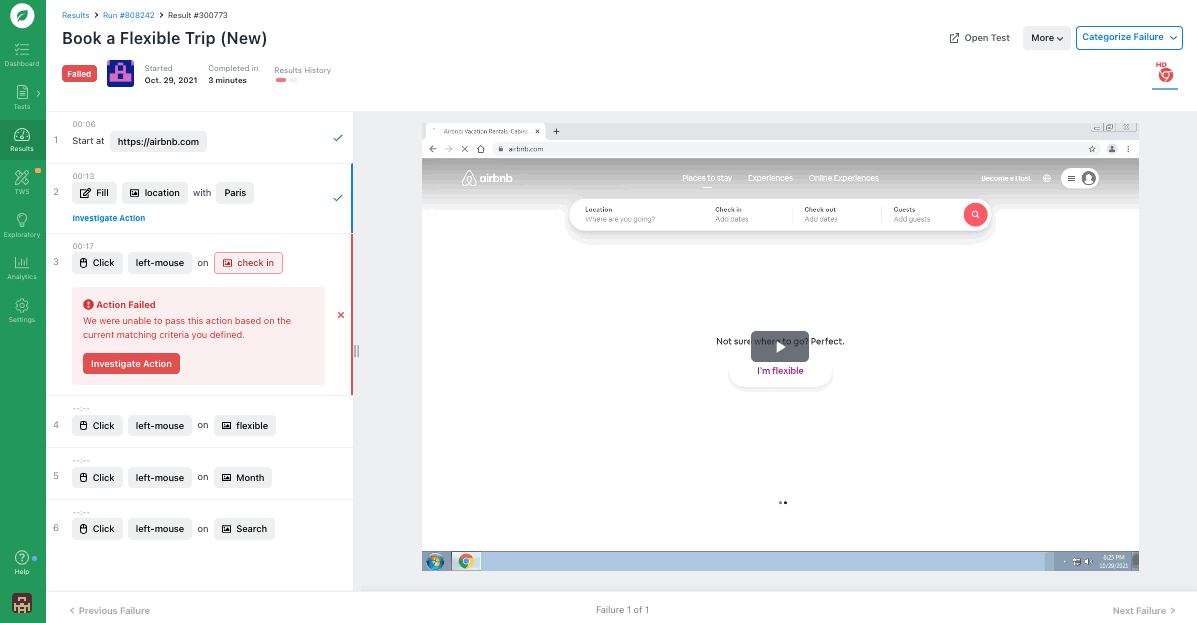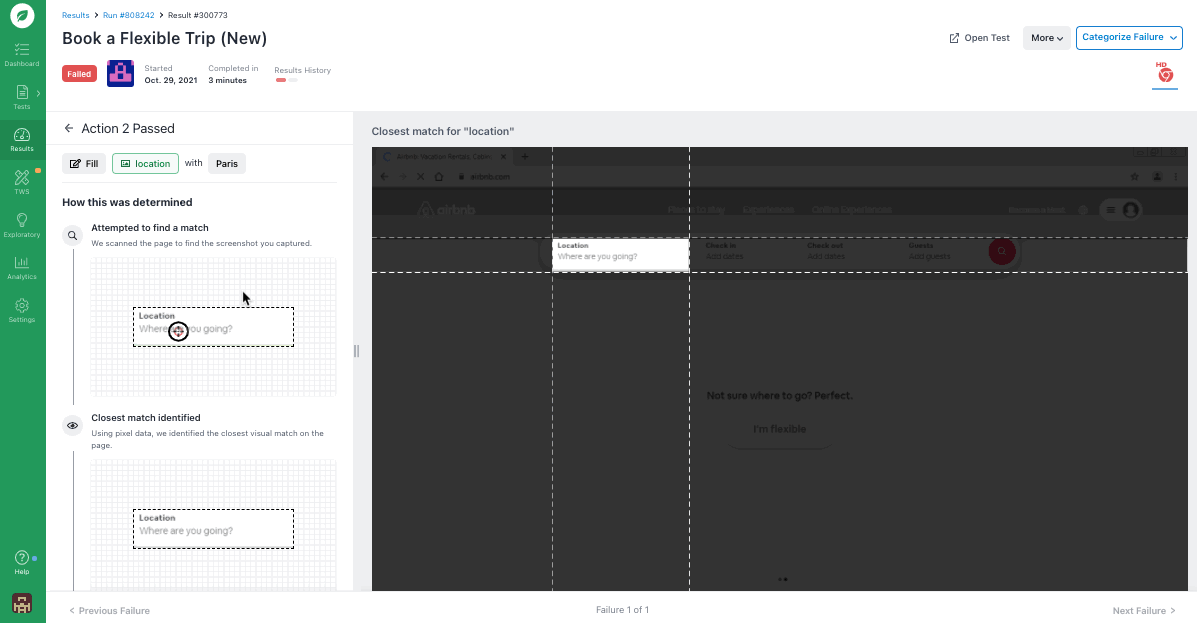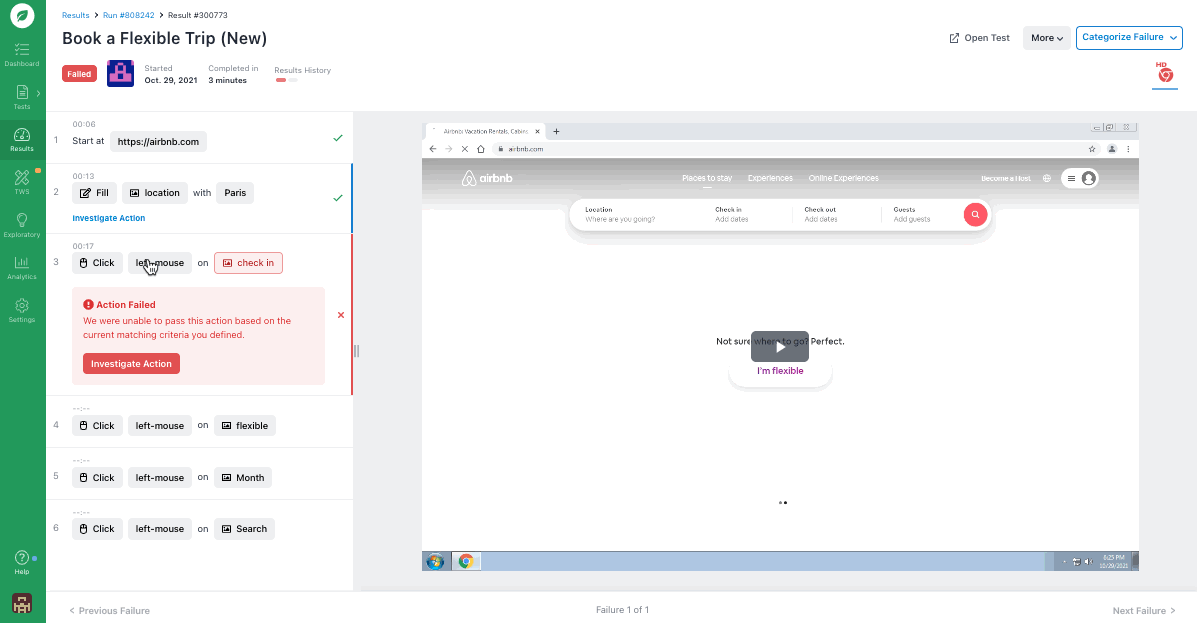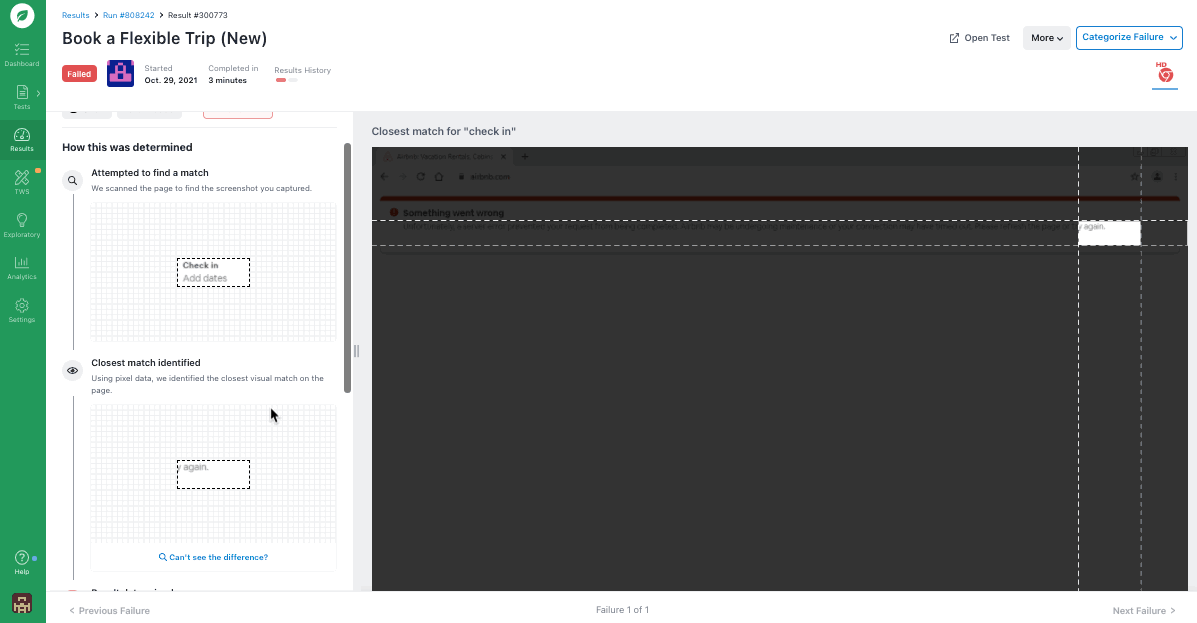
Looking at the set of steps in the screenshot below, anyone can follow along and understand what’s happening in the test:

And if a test fails, the test step that failed during a test run will be highlighted in red along with a brief message describing the failure:

For failures that have a less obvious cause (as is often the case with flaky tests), you can investigate further with:
- Video replays: Rainforest QA records a video of every test, whether it passes or fails. You can compare each test run to quickly see if anything in the app UI changed between runs. Video replays also show you exactly how the failure would’ve appeared to a real user, which can help you decide how important it is to fix the failure.
- “Investigate Action”: Clicking “Investigate Action” for any step allows you to take a closer look at how the step was performed. You can see the original element the test was searching for, the closest match the test found, what percent of a match it was, and more.
- Behind-the-scenes data. Each video recording also captures HTTP logs, browser logs and settings, network traffic, and more. These details are often the key to identifying failures caused by environmental hiccups.
If the root cause of the failure is an actual bug, Rainforest QA offers a Jira integration so you can automatically create a ticket for the development team. The ticket includes the failed test steps, a screenshot of the failed test step, HTTP logs, and a link to the full test results and video recording in Rainforest. Rainforest also integrates with Slack and Microsoft Teams, so you can get instant notifications of any test failure.
Best Practices to Prevent Flaky Tests
Although it’s difficult to completely eliminate flaky tests in automated testing, there are ways to minimize the number of flaky tests you run into:
- Configure automatic retries. As we mentioned above, one of the most common ways to handle flaky tests is to rerun them. The automatic retry feature in Rainforest QA automates this task for you so there are fewer interruptions to your workflow. In Rainforest, you can adjust settings so that each failed test is rerun until it passes, or up to the number of retries you define:

- Execute tests using virtual machines instead of real devices. Rainforest QA uses virtual machines for all test execution because it creates a more controlled test environment. When using real devices, many additional configuration factors could be introduced that could cause test flakiness. Unless you have access to all of the devices used for testing, it could be very difficult to discover what caused the test to fail.
- Throttle your test suite. You can throttle your Rainforest test suite so that fewer tests run at the same time. If your test environment or test data is set up to only handle a few users at a time, this could help minimize test failures due to slow load times caused by user concurrency overload.
- Adjust test action wait times and timeouts. By default, Rainforest QA puts a two-second delay between test actions to allow an app or web page to finish loading. If the test is unable to locate the element, it will wait an additional two minutes before marking that step as failed. These wait times can be changed in your settings, and you can also add additional wait times to individual test steps.
Finally, good test data management can help mitigate flaky tests. As we mentioned above, if multiple tests use the same set of user data, then running tests at the same time could create collisions. To avoid these collisions, you have a few options:
- Create a unique set of users if the order of test runs is causing flakiness.
- Include steps at the beginning of each test to create a new user with every test run. (Rainforest makes this option easy by offering a library of random and unique names, emails, passwords, etc.)
- Run tests that use the same user account in asynchronous test runs.
If you have multiple tests that use the same user account, you’ll want to use reset protocols. Whether you reset the testing environment before every test or add steps to your tests to revert to a default state, resetting is important for reducing inconsistent test results.
For example, let’s say you have a test that verifies a user can change their username. If the username isn’t subsequently reset to the original username, every other test that uses that username will fail.
Easily Handle Flaky Tests with Rainforest QA
With Rainforest QA, anyone can quickly figure out if a test is flaky or permanently broken, or if the software has a bug. It’s a scalable, all-in-one quality assurance solution that’s appropriate for small teams just getting started with automated testing or QA-mature teams regularly running 500+ automated software tests as part of their CI/CD pipeline.
Talk to us about setting up a Rainforest plan that fits your needs.