

The right AI tools make all the difference in QA testing
AI has officially entered every corner of software testifng. The hard part now is figuring out which tools and features actually save time, speed releases, and (most importantly) improve quality outcomes.
According to a recent survey from Test Guild, 72.8% of testers are prioritizing AI-powered QA for 2026. This includes tools that handle test planning, test management, test writing, and even analyzing test results.
AI software testing tools: What you need to know
AI can make the biggest impact on tedious, rote, and time-consuming steps in the automated testing process, including test suite creation and expansion, triage, and maintenance.
However, that impact depends heavily on how AI is applied. AI layered onto fragile testing foundations tends to accelerate existing problems. AI designed into the testing model itself can significantly lower the cost of QA while improving reliability.
AI software testing solutions generally take two broad approaches to using AI in test automation: AI-assisted test creation and maintenance, and autonomous AI testing.
In this piece, we’ll focus on no-code QA automation tools, which are generally a strong fit for startups and scale-ups. Larger teams with complex testing requirements often choose open source tools like Playwright or Selenium, but these tools require significant engineering involvement because they are script-based by nature.
That said, even some larger, more mature organizations are starting to adopt more lightweight no-code QA automation tools to extend their coverage without increasing the workload for quality engineers. This can be a very effective way to enable non-technical QA testers and other roles on the team to contribute to quality assurance without having to learn code.
AI software testing tools for test creation and maintenance
Test creation with AI
Creating automated tests with AI prompts is now table stakes in QA. Nearly every modern AI testing platform offers some version of “describe it in plain English, and we’ll turn it into a test.”
In the most common model, generative AI translates a prompt like “log in and verify the dashboard loads” into an executable script. Tools such as Rainforest QA, testRigor, Reflect, Autify, and Functionize use this approach to speed up test creation and lower the barrier for teams that don’t want to write code or manage selectors directly.
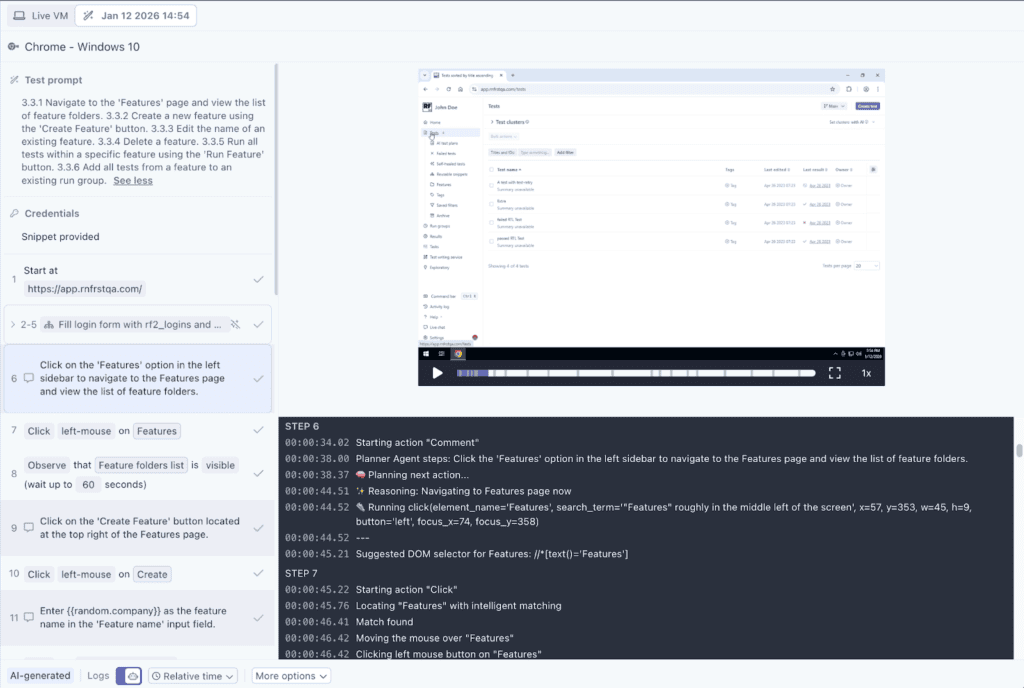
Caption: Example of no-code test scripting in Rainforest QA with plain-English prompts.
Other tools take a less direct path. Platforms like ProdPerfect and Meticulous generate tests by observing real user behavior or recorded sessions in pre-production, using AI to infer which flows should be tested without requiring explicit prompts. In these cases, test creation happens automatically based on how the product is actually used or built.
Test maintenance with AI
Keeping automated tests up to date has always been a tedious part of QA. As applications evolve, tests inevitably break. This is not typically because the product is broken, but because the test no longer matches the product reality. Historically, teams had to manually investigate every failure to answer a basic question: Is this a real bug, or is the test just outdated?
Over time, this creates a familiar downward spiral. Tests fail frequently. Teams stop trusting the results. Failures get ignored or deferred. Eventually, the test suite becomes all noise and very little signal.
AI has meaningfully changed this part of the QA workflow without completely eliminating human judgment. Modern AI testing tools can now handle several categories of test maintenance well in many cases, including:
- Detecting minor, intended UI changes (like renamed buttons, moved elements, or updated layouts)
- Recreating broken steps when a user flow still exists but is implemented slightly differently
- Re-running and validating updated tests more quickly and with fewer manual checks
- Distinguishing between “the test broke” and “the flow broke” with much higher accuracy than before
With Rainforest QA, this takes the form of practical self-healing. When a software test fails because the application changed in an expected way, the AI attempts to regenerate the relevant parts of the test and return it to a passing state. The team is notified, but non-critical, expected-change failures don’t have to block a release. This gating model means developers don’t have to drop everything to fix a test that was never protecting real value in the first place.
This works especially well for:
- Visual or structural UI changes
- Copy updates and small interaction changes
- Refactors that preserve user intent but alter implementation
- High-churn areas of the product where maintenance used to dominate QA time
Where AI doesn’t work (and shouldn’t pretend to) is in deciding what the application should do. When a core user flow is genuinely broken, the test should fail. In those cases, AI shouldn’t paper over the problem by taking a meandering path that a real user would never take. A small but critical percentage of failures reflect real, release-blocking bugs, and those require human attention and judgment. That’s not a limitation of AI—it’s the whole point of QA.
The biggest shift since earlier generations of AI software testing tools isn’t that maintenance disappeared. It’s that AI now absorbs the mechanical effort of keeping tests aligned with reality, so humans can focus on interpreting failures and making decisions.
As the barrier to creating and maintaining tests gets lower, the importance of human judgment actually increases, not decreases.
AI makes it easier than ever to create and maintain tests. Humans still have to decide which ones belong in the test suite.
What to look for with AI-assisted test creation and maintenance
AI can dramatically improve the speed and efficiency of automated testing, but only if it’s applied thoughtfully and in the right places. As test creation and maintenance get easier, the risk shifts from doing too little to doing too much — or at least too much of the wrong things. To evaluate AI software testing tools effectively, it helps to understand three practical realities about how AI actually behaves in QA workflows today.
1. AI isn’t ready to take over all test maintenance
AI has made meaningful progress in test maintenance, especially when applications change in small, intentional ways. When user intent stays the same but the implementation shifts, many AI software testing tools can execute the test again, adapt broken steps, and return it to a passing state without human involvement.
In many scenarios, AI for QA tools excel at execution and adaptation. They can observe what changed, infer how to complete the same task, and keep tests aligned with the current version of the application.
Where AI often falls short is in understanding why a change was made and what should be tested instead. When functionality changes in a meaningful way (new business logic, altered user journeys, or different success criteria), AI doesn’t have the product context to decide whether an existing test is still valid or whether new coverage is required. Those decisions require human input to evaluate customer impact, release risk, and business priorities.
This limitation is especially pronounced in code-based testing frameworks, where tests validate source code rather than user behavior. When implementation changes, tests fail noisily, and AI is left guessing how to repair them without a reliable signal of intent. On the flip side, AI software testing tools that are overly agentic and don’t keep humans in the loop may force-pass tests when they should, in fact, fail and require fixes.
AI can reduce the mechanical effort of maintenance, but it doesn’t replace judgment. It executes and adapts well; it does not decide what matters.
2. You can’t trust AI outputs that aren’t transparent
AI in testing tools behaves much like AI coding assistants: it can accelerate work, but its outputs need to be understandable and predictable. When AI decisions are opaque or when the same input produces different behavior across runs, teams lose confidence in their test results.
This is especially risky in QA. Software tests aren’t just automation artifacts; they’re release signals. If a team can’t tell why a test exists, what it’s validating, or why it failed, that test quickly becomes noise.
Effective AI software testing tools make AI behavior transparent and explainable. They allow teams to see:
- What changed in a test
- Why a test was updated or healed
- Whether a failure reflects a real product issue or an outdated assumption
Without this transparency, AI doesn’t reduce cognitive load; it increases it. Teams spend time second-guessing results, re-running tests, and manually validating outcomes they no longer trust.
In QA, reliability and explainability matter more than clever automation. AI should clarify signals, not obscure them.
3. AI doesn’t consistently save time when layered onto code-based open source testing tools
AI doesn’t operate in a vacuum. Its effectiveness depends heavily on the foundation it’s built on.
In our 2024 developer survey, teams using open-source frameworks like Selenium, Cypress, or Playwright reported spending more time on test creation and maintenance, even when AI was part of their workflow.
[Placeholder for “Teams spending” graphic]
This isn’t because AI is ineffective. It’s because AI is being layered on top of tools that were designed to be driven entirely by humans. Open-source frameworks tend to be code-centric and tightly coupled to implementation details, which means tests break frequently as applications evolve. AI may speed up test generation, but it doesn’t change the underlying brittleness.
When AI is applied on top of complex, fragile systems, it often increases noise without reducing failure rates. The result is more tests, more failures, and more time spent sorting signal from noise.
To deliver actual time savings, AI is best layered on top of lightweight, flexible QA systems—often no-code automation platforms. These are best for growing companies that need to prioritize user experience, reduce brittleness by design, and minimize the amount of human intervention required over the lifetime of a test.
Building reliable QA with AI
AI can be a powerful force multiplier in QA, but only when it’s used with clear boundaries and the right foundation. The most effective AI software testing tools don’t try to replace human judgment or paper over brittle systems; they focus on reducing low-leverage work while offering visibility so humans can make strategic decisions.
What AI software testing tools shouldn’t do is hide their decisions, force-pass failures, or encourage teams to produce more tests than they can justify or maintain. In the end, AI can make it easier than ever to build and run tests, but quality still depends on people who can decide what matters, what’s risky, and what should block a release.
If you’re ready to explore Rainforest QA’s AI-accelerated features, talk to us about setting up a personalized demo.