

Our customers want to deploy fast and not be slowed by uncertain delays. One way to tighten their release cycle is by estimating well when a test run completes. However, estimates are hard because each customer has their own tests and environments, and yet being off by minutes or more could add that much to their release cycle.
For Rainforest, sometimes a run going longer than expected might indicate a problem, now or imminent, in our infrastructure, and we want to detect abnormal cases as they, or better, before they, occur.
Method: Predicting “Normal” Test Run Length
So how would one predict how long a test execution run would take? What would a “normal” run look like? One way is to look at our tests, and then estimate how long the given actions would take, based on past runs. But how do you determine an action? We don’t look at our testers while running in their VMs. Instead, we look at each step description and pick out the verbs as proxy. Each verb, or set of verbs, is then associated with the amount of time that step took, and we do this for all the past runs we have available.
Results
 figure: Sorted descendingly by frequency. Our counts reveal profiles for various actions, and they even suggest that some actions are quite similar across testers.
figure: Sorted descendingly by frequency. Our counts reveal profiles for various actions, and they even suggest that some actions are quite similar across testers.
Assuming Additive
As a test is just a series of steps, we add up the step times to arrive at a test time. We also include the stages of launching a run, waiting for callbacks, launching a VM, and so on, to come up with a setup time.
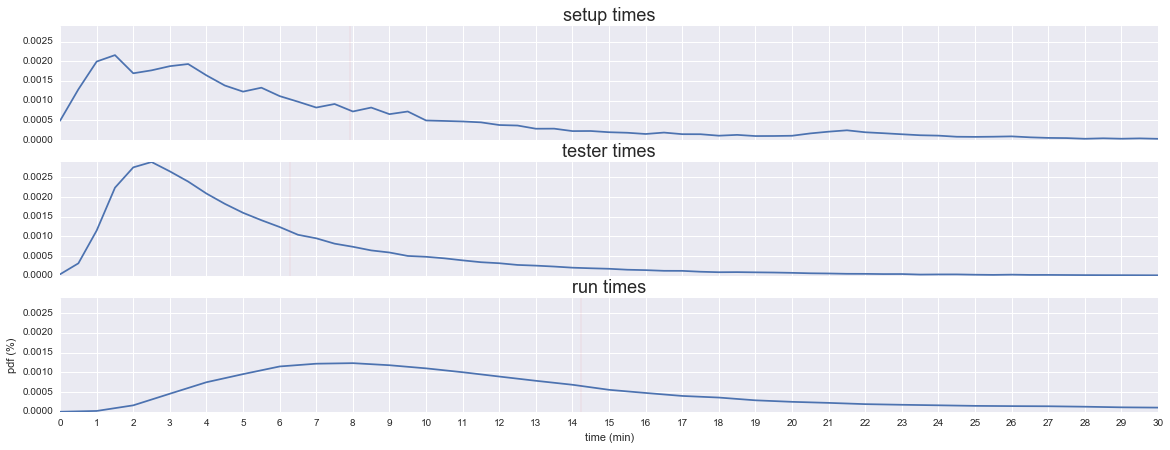 figure: Most setup and most testers bunch into a typical amount of time taken, but there is a wide range in both cases.
figure: Most setup and most testers bunch into a typical amount of time taken, but there is a wide range in both cases.
Now strictly speaking each of the setup stages and test steps can affect the next one’s, but we assume they act independently, which allows us to add up the times, across stages and steps, to come up with a total run time. That they act independently isn’t strictly true, but even if this model is wrong, it could still be useful.
Validation
The last part in any model building is checking whether it works, and that involves looking at the future, and seeing if we made correct predictions.
 figure: Validation of the run time
figure: Validation of the run time
Our model makes stable predictions, as the error profiles are quite close across different times.
However, though the average error is near zero, the large range of times require a corrective factor when reporting a single number (rather than a range or distribution) so to ensure an accurate, upper limit.
Takeaway: Detecting Abnormal Test Execution Runs More Effectively
With the corrective factor, we can with high confidence tell our customers at most how long their run with take. As well, now that the model defines what is a “normal” run, we can begin to automatically detect “abnormal” runs.
Though the predicted error profile might be stable across time, it could be more precise. Future work would involve uncovering more factors that determine a run’s typical length and variations in total time. We have already made use of the findings to help speed up some customer’s tests, and for guiding projects with data about what analysis or changes to our infrastructure would have the biggest impact, whether directly on the release cycle or, relatedly, on results quality.
We’re always working to improve our test execution engine, and hope to have shed some insight into how we’re continually improving Rainforest results. Have questions about how we’re making use of data in our analyses or algorithms? Let us know!